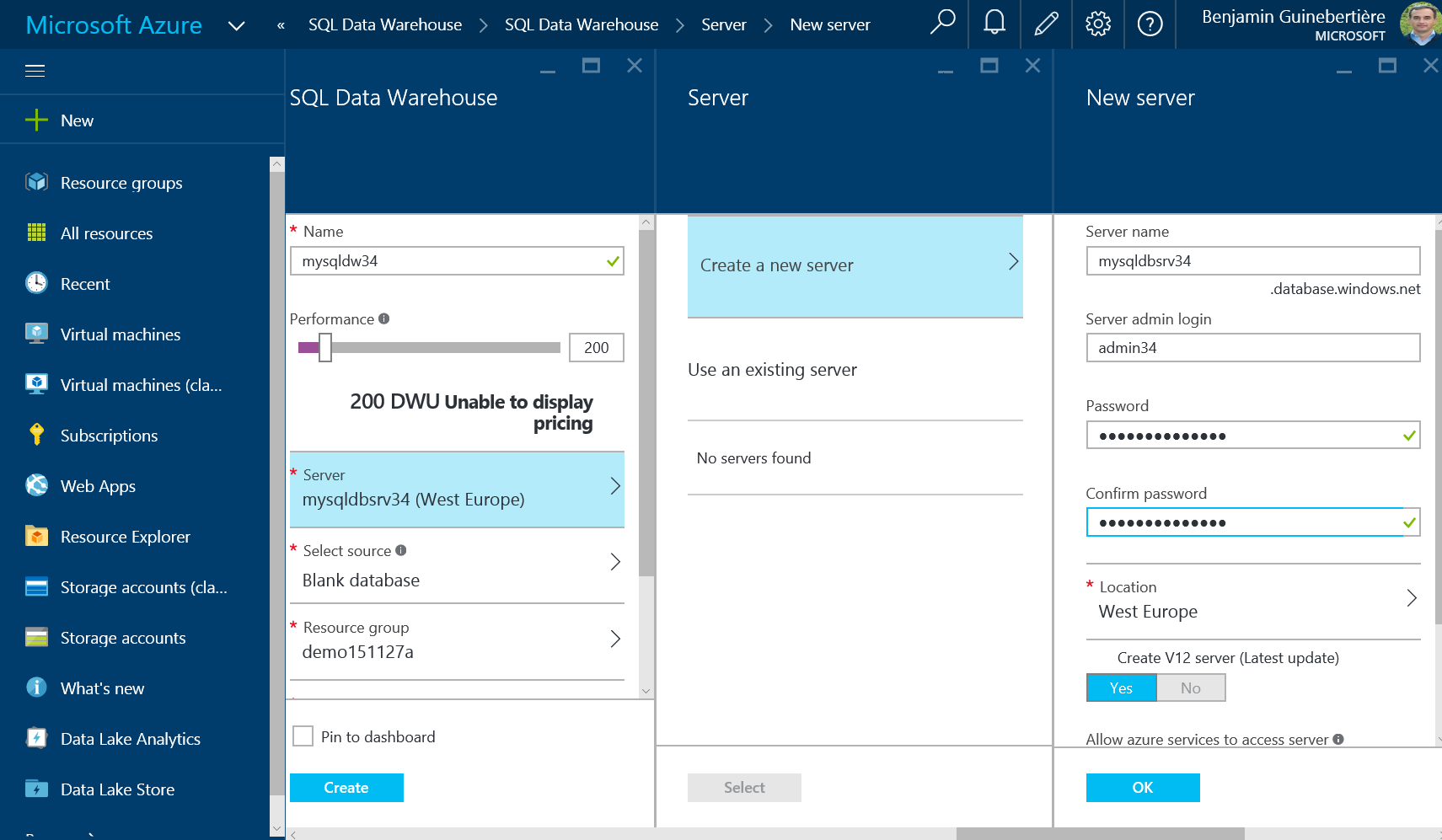
This is a sample. By convention, all values ended by 34 should be replaced by your own values. For instance, the data storage account is mydata34. Yours should have a different name.
the sample dataset
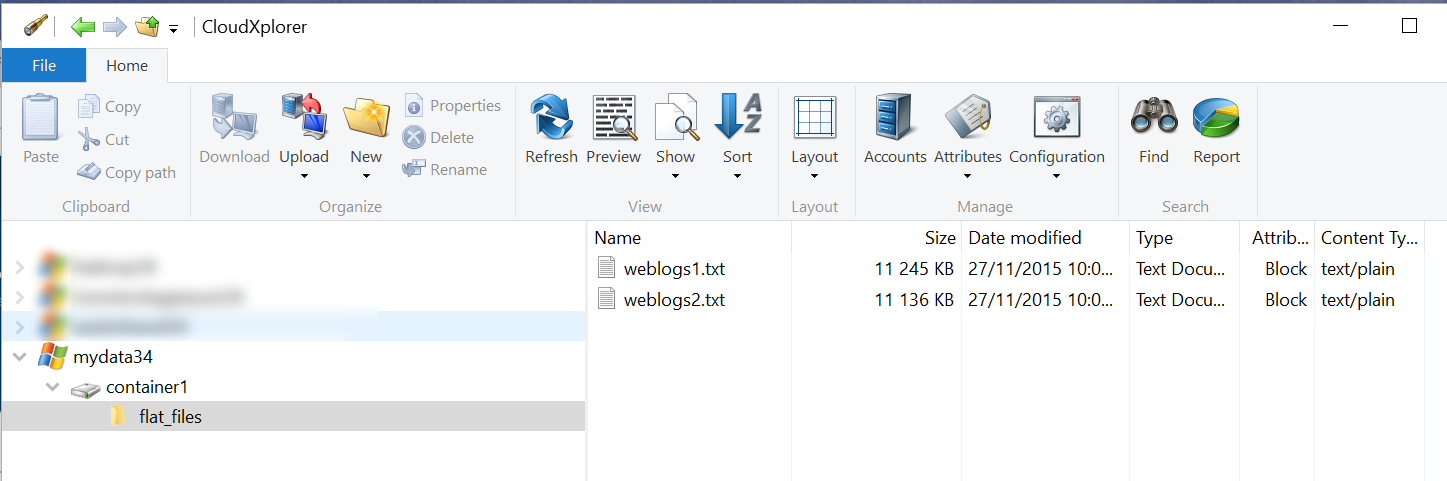
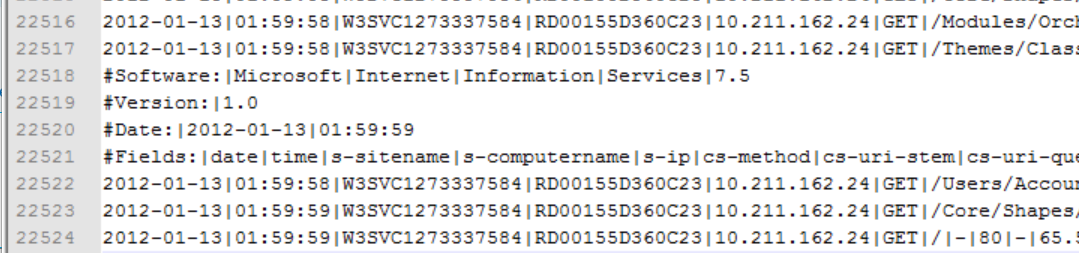
The data is available as a number of flat delimited files in a blob storage container. In this example, there are 2 files. here are a few lines of data:
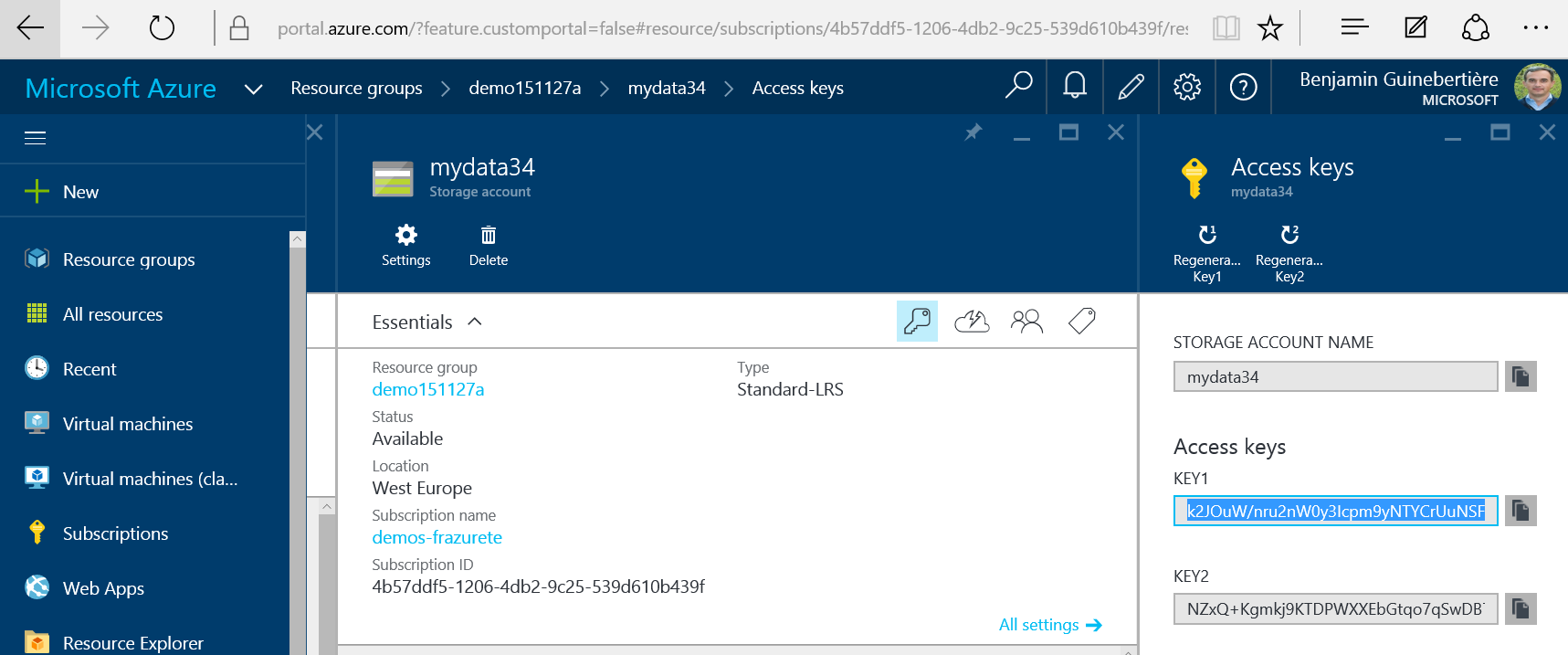
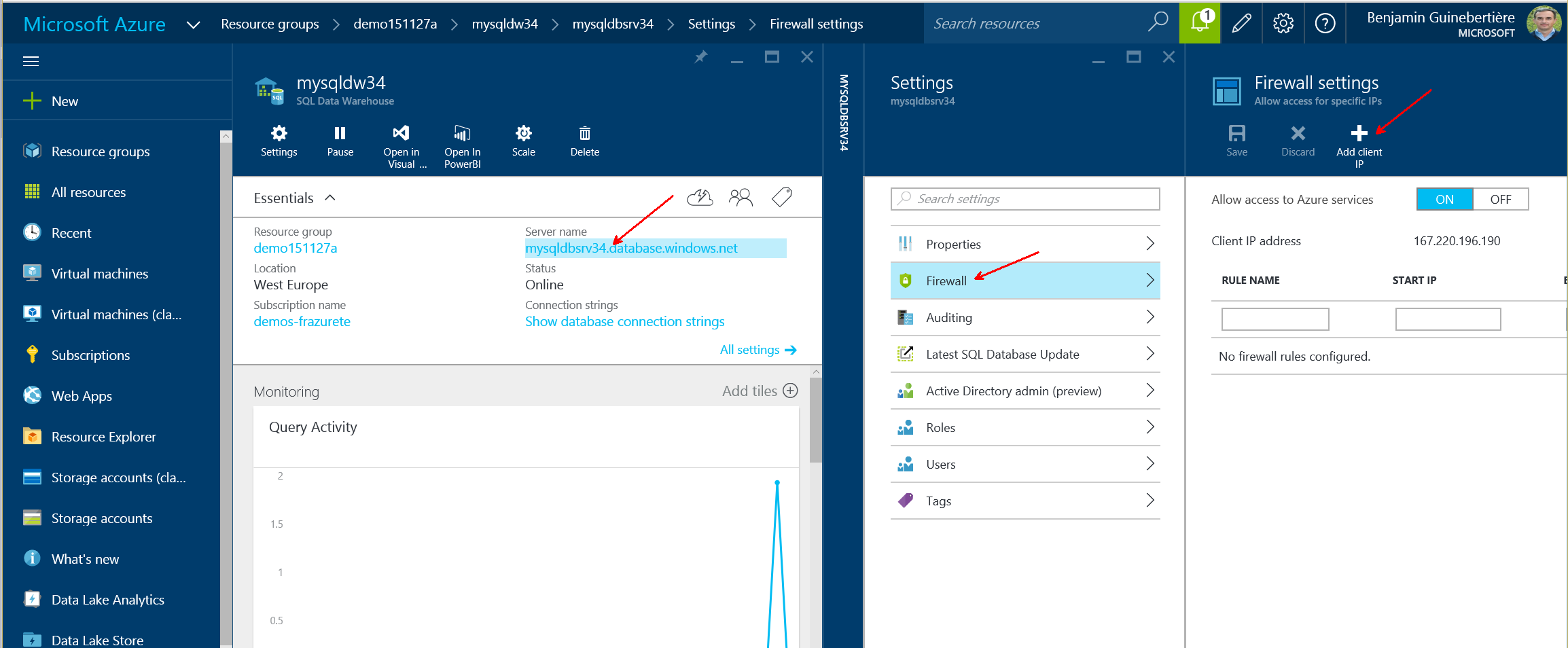
In this example, the storage account name is mydata34 and its key is k2JOuW/nru2nW0y3Icpm9yNTYCrUuNSFm9RDyMuBvIKuYqhtPHAK8MW4bVQfWssXp184pGhlKraaOc7sZTDijQ==.
The key can be found in the portal, for example:
NB: by the time your read this page, the key may have change. I share the key so that you can find it in code where it is necessary.
-- create table as select: https://azure.microsoft.com/en-us/documentation/articles/sql-data-warehouse-develop-ctas/ CREATE TABLE [dbo].[mydata] WITH ( DISTRIBUTION = ROUND_ROBIN, CLUSTERED COLUMNSTORE INDEX ) AS SELECT * FROM mydata_externaltable;
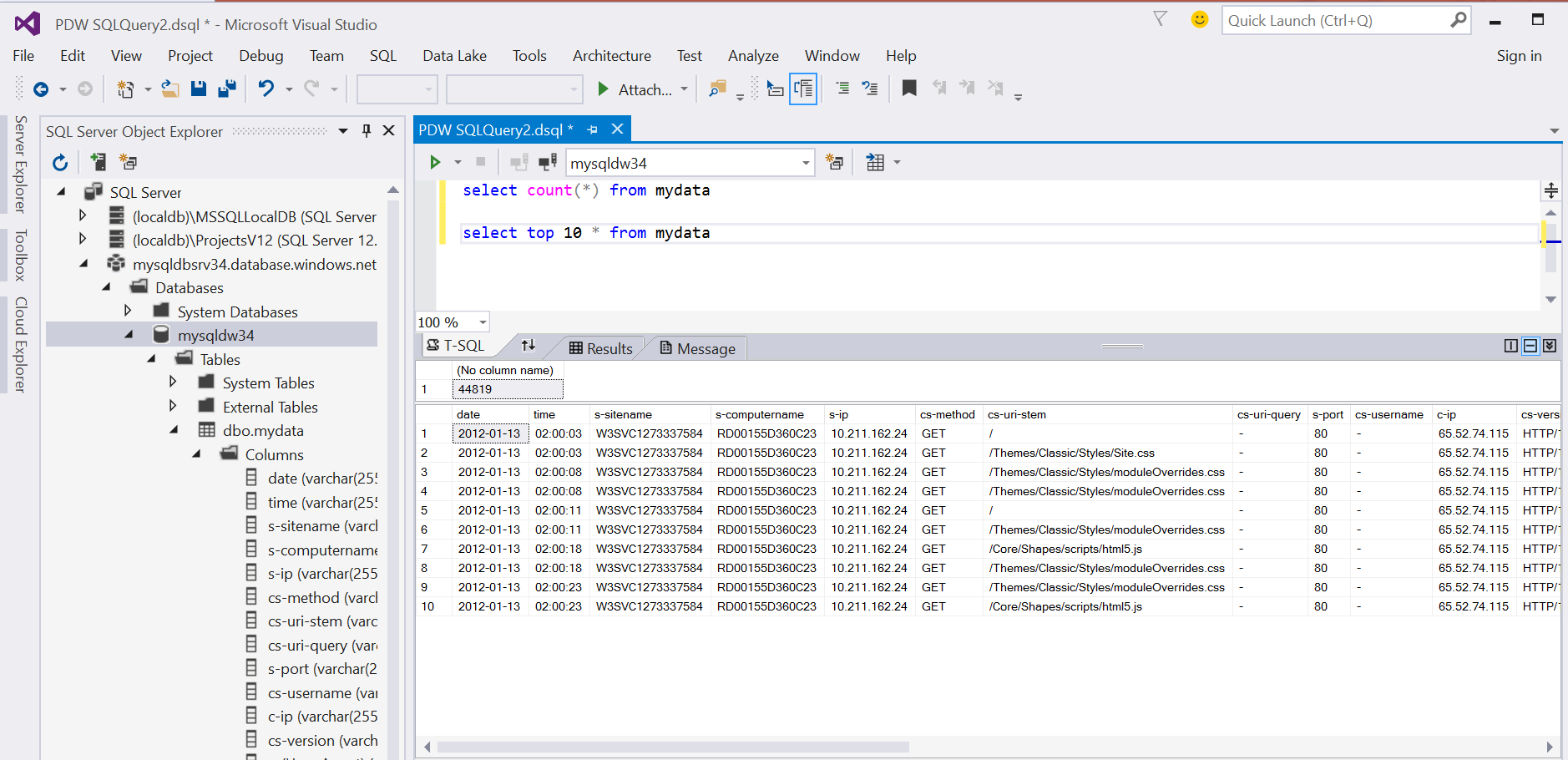
the result of the last statement is
1 2 3 4 5 6 7 8 9 10
(44819 row(s) affected) Query completed. Rows were rejected while reading from external source(s). 4 rows rejected from external table [mydata_externaltable] in plan step 5 of query execution: Location: '/flat_files/weblogs1.txt' Column ordinal: 6, Expected data type: VARCHAR(255) collate SQL_Latin1_General_CP1_CI_AS, Offending value: #Software:|Microsoft|Internet|Information|Services|7.5 (Tokenization failed), Error: Not enough columns in this line. Location: '/flat_files/weblogs1.txt' Column ordinal: 2, Expected data type: VARCHAR(255) collate SQL_Latin1_General_CP1_CI_AS, Offending value: #Version:|1.0 (Tokenization failed), Error: Not enough columns in this line. Location: '/flat_files/weblogs1.txt' Column ordinal: 3, Expected data type: VARCHAR(255) collate SQL_Latin1_General_CP1_CI_AS, Offending value: #Date:|2012-01-13|01:59:59 (Tokenization failed), Error: Not enough columns in this line. Location: '/flat_files/weblogs1.txt' Column ordinal: 21, Expected data type: VARCHAR(255) collate SQL_Latin1_General_CP1_CI_AS, Offending value: |time-taken (Tokenization failed), Error: Too many columns in the line.
each file has ~22000 lines so the total numlber of lines seems good.
The rejected lines are some headers that are inside regular rows:
We can now query the data:
Azure Machine Learning
Let’s now get a subset of the data in Azure Machine Learning. For example, the query we need is
1
select top 1500 * from mydata WHERE [sc-status]='200' ORDER BY date, time asc
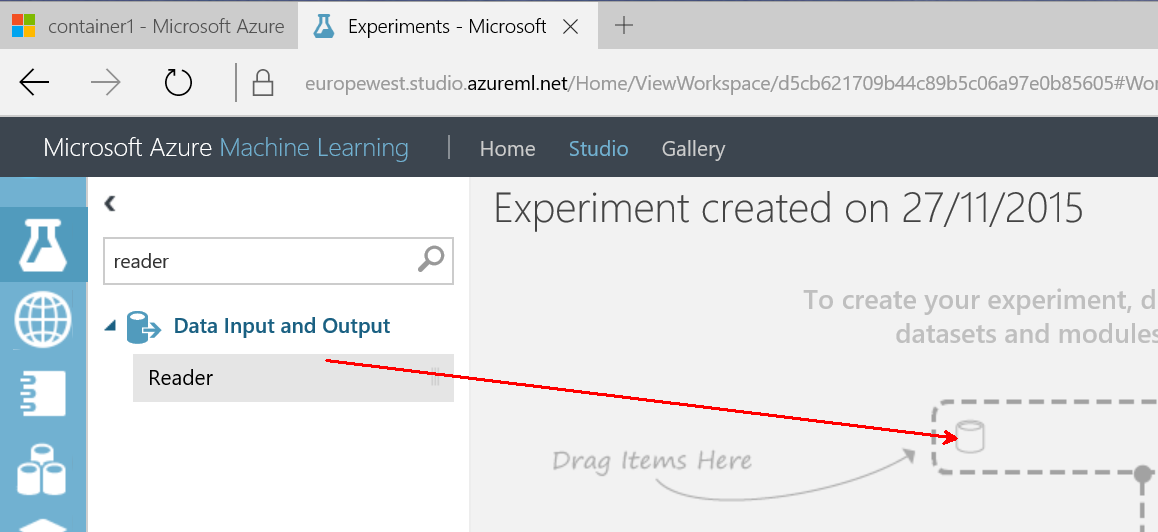
Let’s assume you have an Azure Machine learning available. You’ve created a new experiment from the Studio at studio.azureml.net.
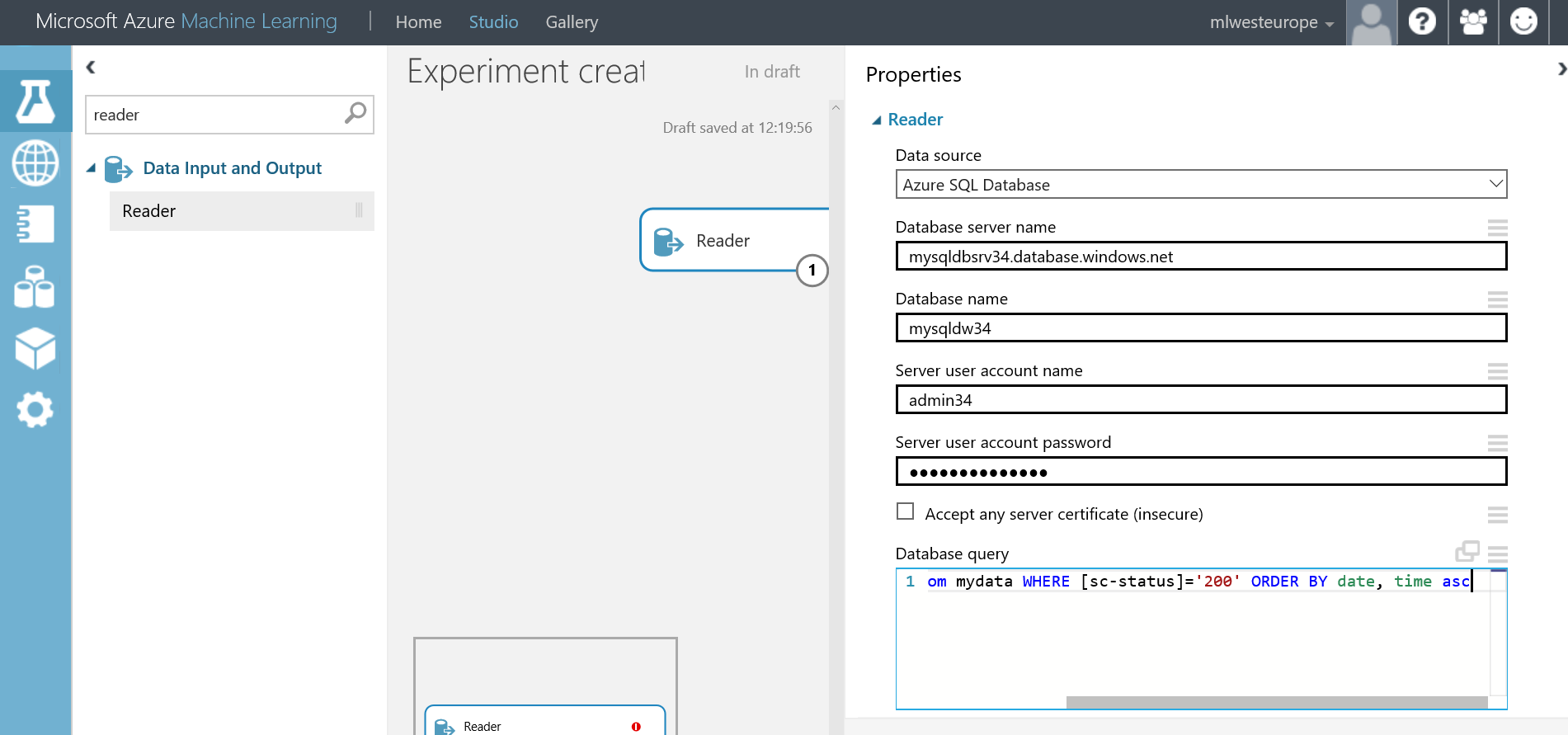
Then add a reader
In the properties, choose and fill:
Azure SQL Database
mysqldbsrv34.database.windows.net
mysqldw34
admin34
DDtgjiuz96____
select top 1500 * from mydata WHERE [sc-status]=’200’ ORDER BY date, time asc
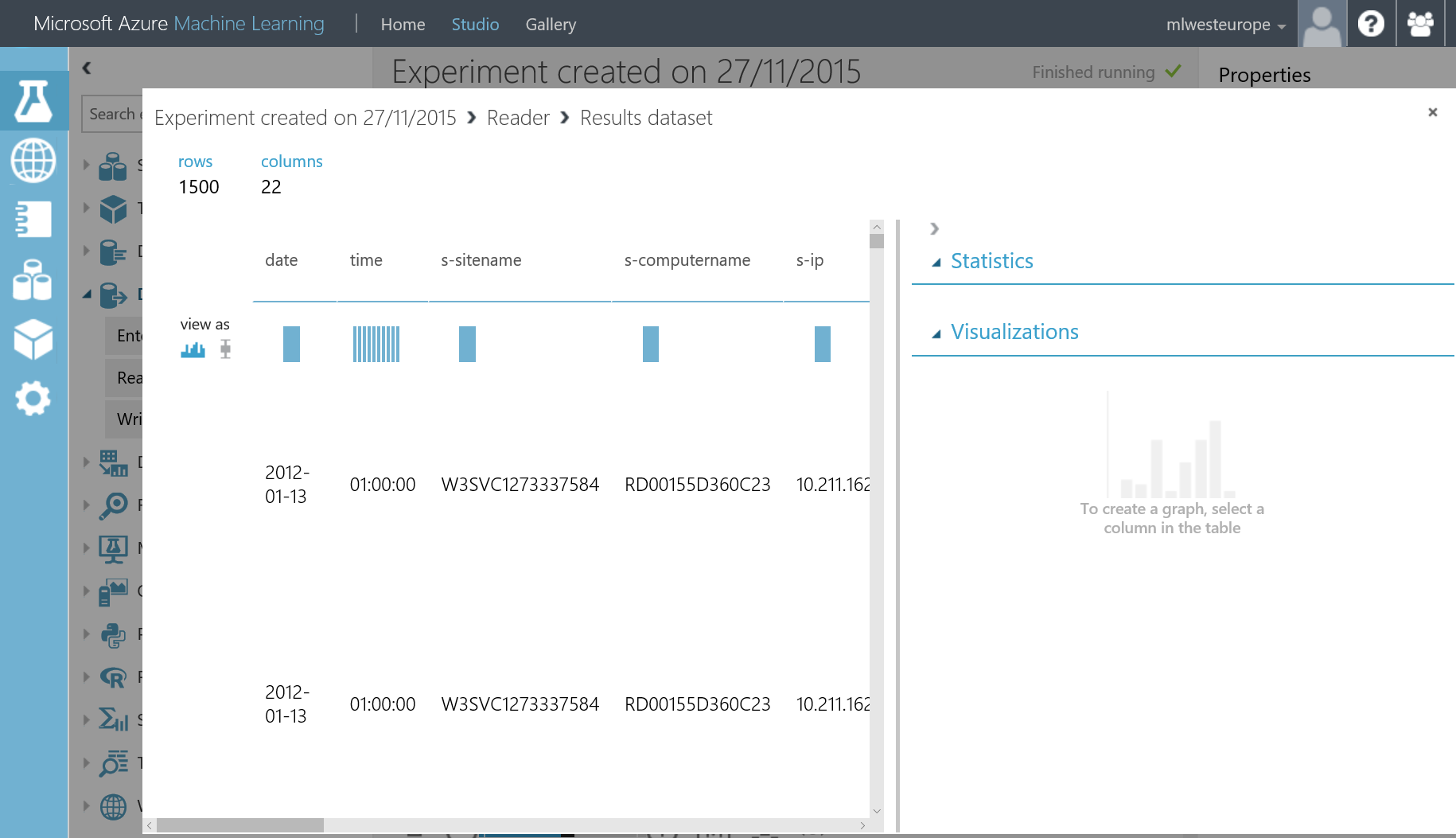
click Run at the bottom of the page, then you can visualize the dataset
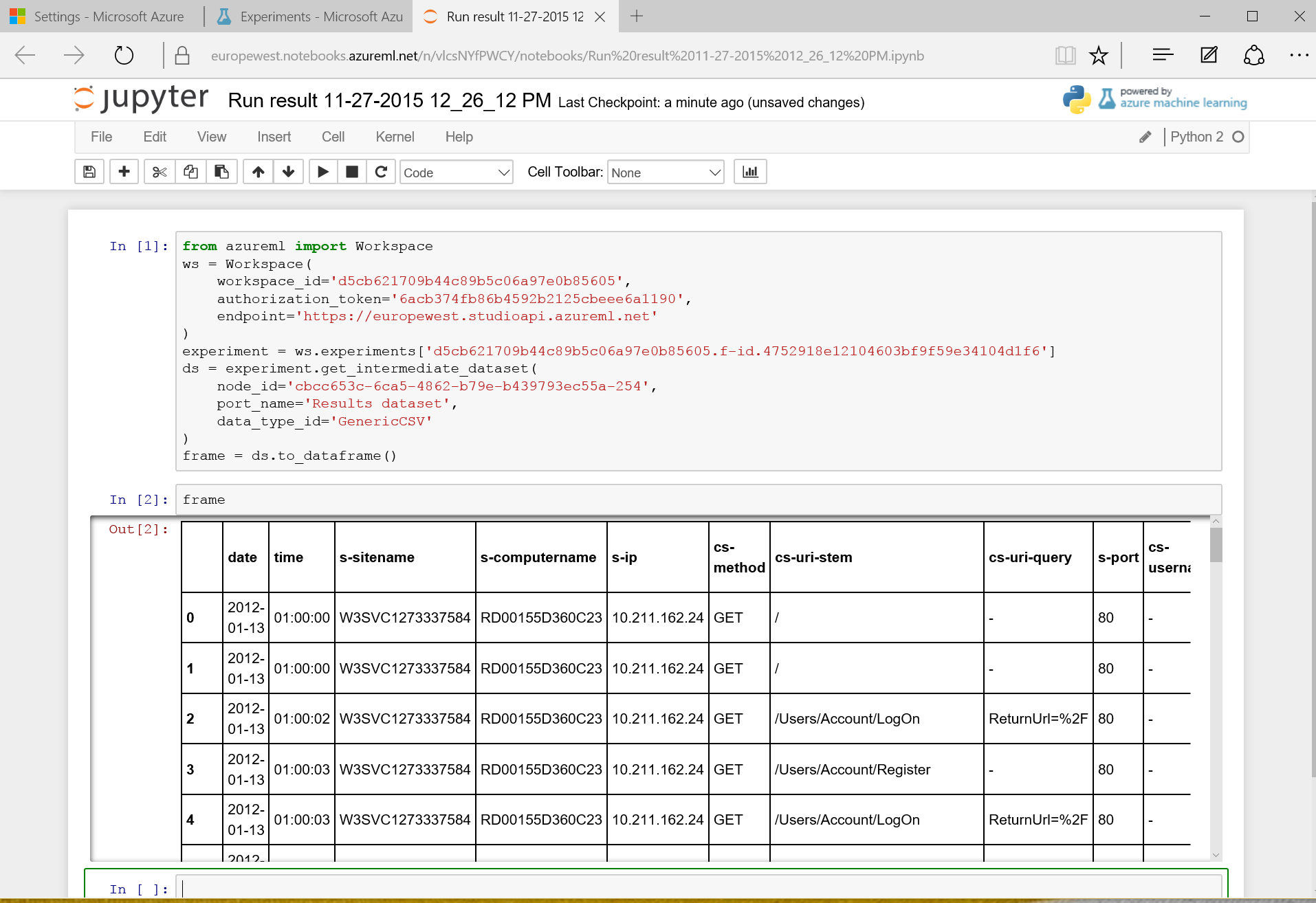
Jupyter
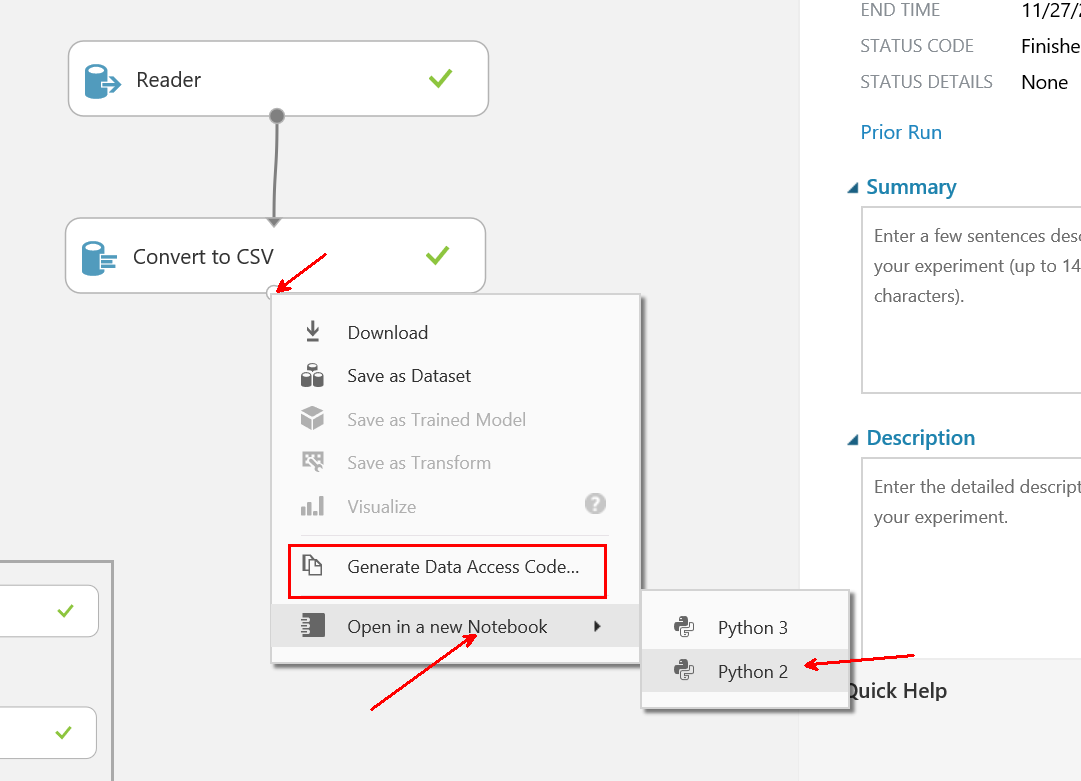
You may also want to use the dataset in a Jupyter notebook. For that, you just have to convert the dataset to CSV and then generate the code to access the dataset from Azure Machine Learning.
Drag & drop the Convert to CSV shape, connect it to the reader. Then you can generate the Python code to access that dataset or directly ask for a new notebook that will have access to the dataset:
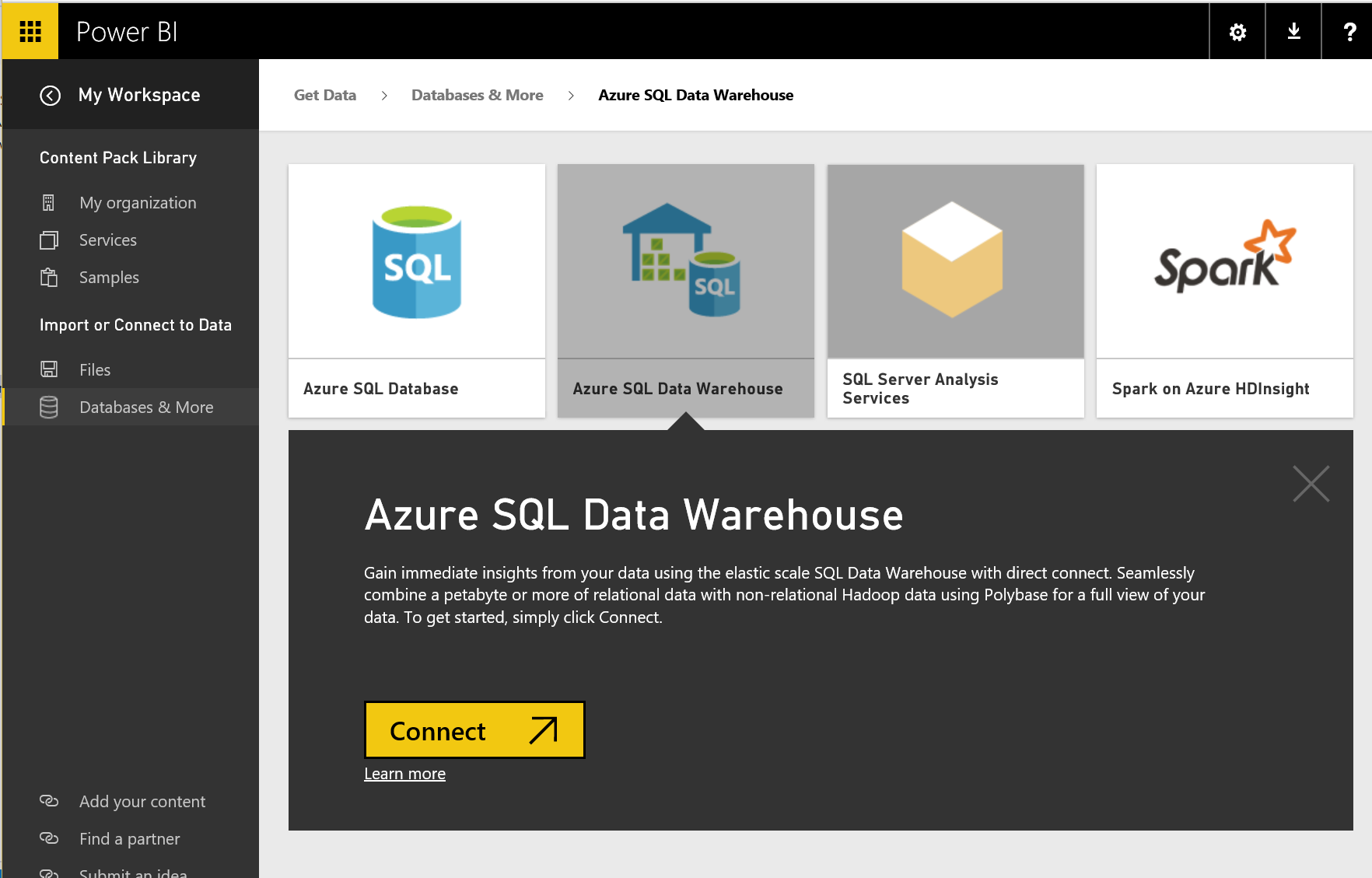
PowerBI
You may also want to see your dataset
For that, you can go to your Power BI environment at app.powerbi.com, choose Get Data, Databases & More and choose Azure SQL Data Warehouse.
mysqldbsrv34.database.windows.net
mysqldw34
Next
admin34
DDtgjiuz96____
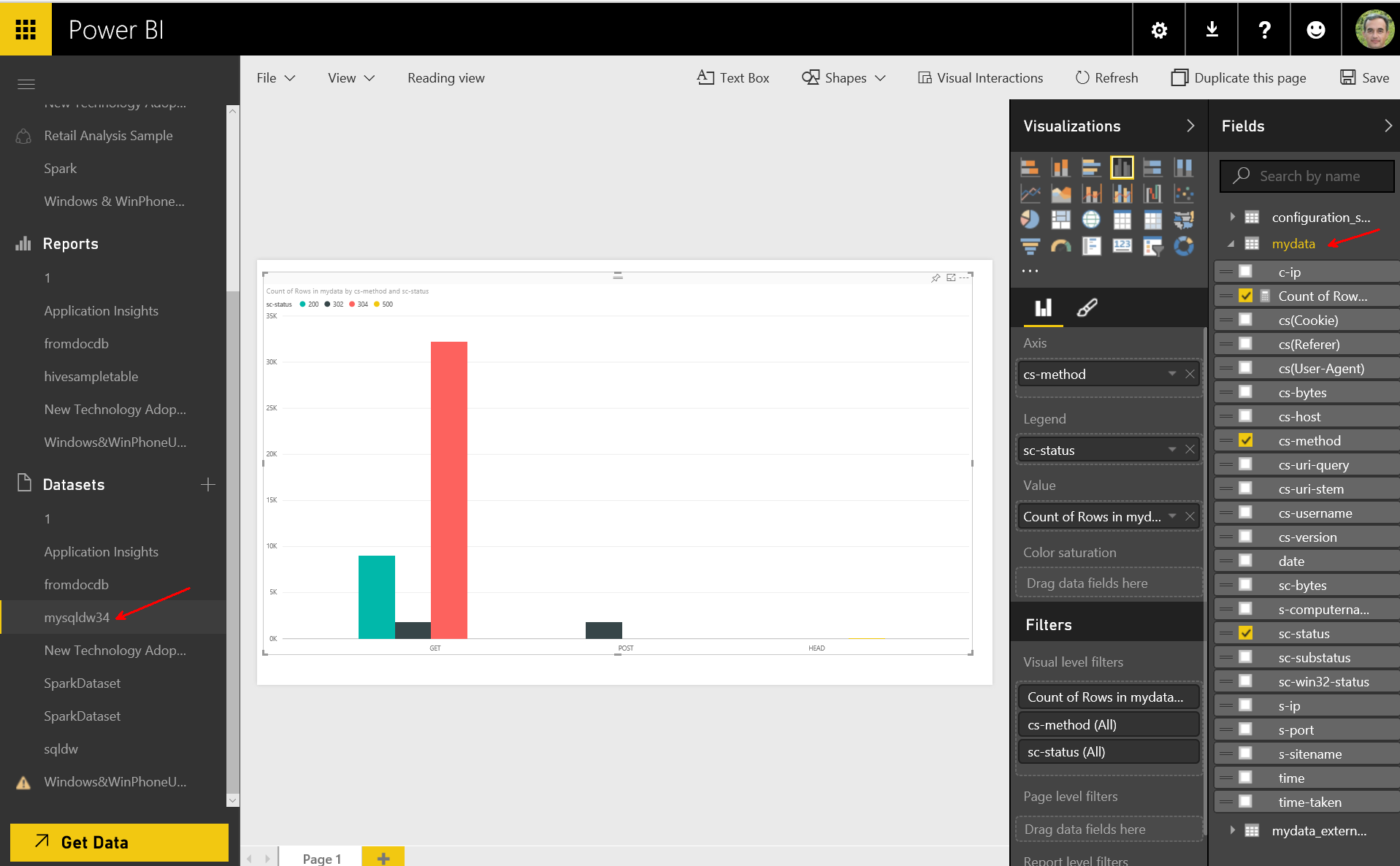
from there, you have the dataset available, and can visualize it:
Conclusion
We saw how to load flat files in a SQL DW, then in Azure Machine Learning and Jupyter, as well as Power BI.